EraseDraw: Learning to Draw Step-by-Step via Erasing Objects from Images

draw_abstract
Abstract
Creative processes such as painting often involve creating different components of an image one by one. Can we build a computational model to perform this task? Prior works often fail by making global changes to the image, inserting objects in unrealistic spatial locations, and generating inaccurate lighting details. We observe that while state-of-the-art instruction-guided editing models perform poorly on object insertion, they can remove objects and erase the background in natural images very well. Inverting the direction of object removal, we obtain high-quality data for learning to insert objects that are spatially, physically, and optically consistent with the surroundings. With this scalable automatic data generation pipeline, we can create a dataset for learning object insertion, which is used to train our proposed text-conditioned diffusion model. Qualitative and quantitative experiments have shown that our model achieves state-of-the-art results in object insertion, particularly for in-the-wild images. We show compelling results on diverse insertion prompts and images across various domains. In addition, we automate iterative insertion by combining our insertion model with beam search guided by CLIP.
Method Overview
We observe that with modern segmentation, captioning and inpainting models, we can perform the task of object removal with high photo and physical realism. With this observation, we propose an autonomous data generation pipeline for generating input-output pairs for the task of instruction-guided object insertion. We modify a wide distribution of images from the internet by erasing objects from them using inpainting models and describing the attributes and locations of the erased objects using vision language models. With this dataset, we train a diffusion model for language-conditioned object insertion. Once we have this model, we are able to we're able to build complex images step-by-step through autoregressively invoking our model on the same image
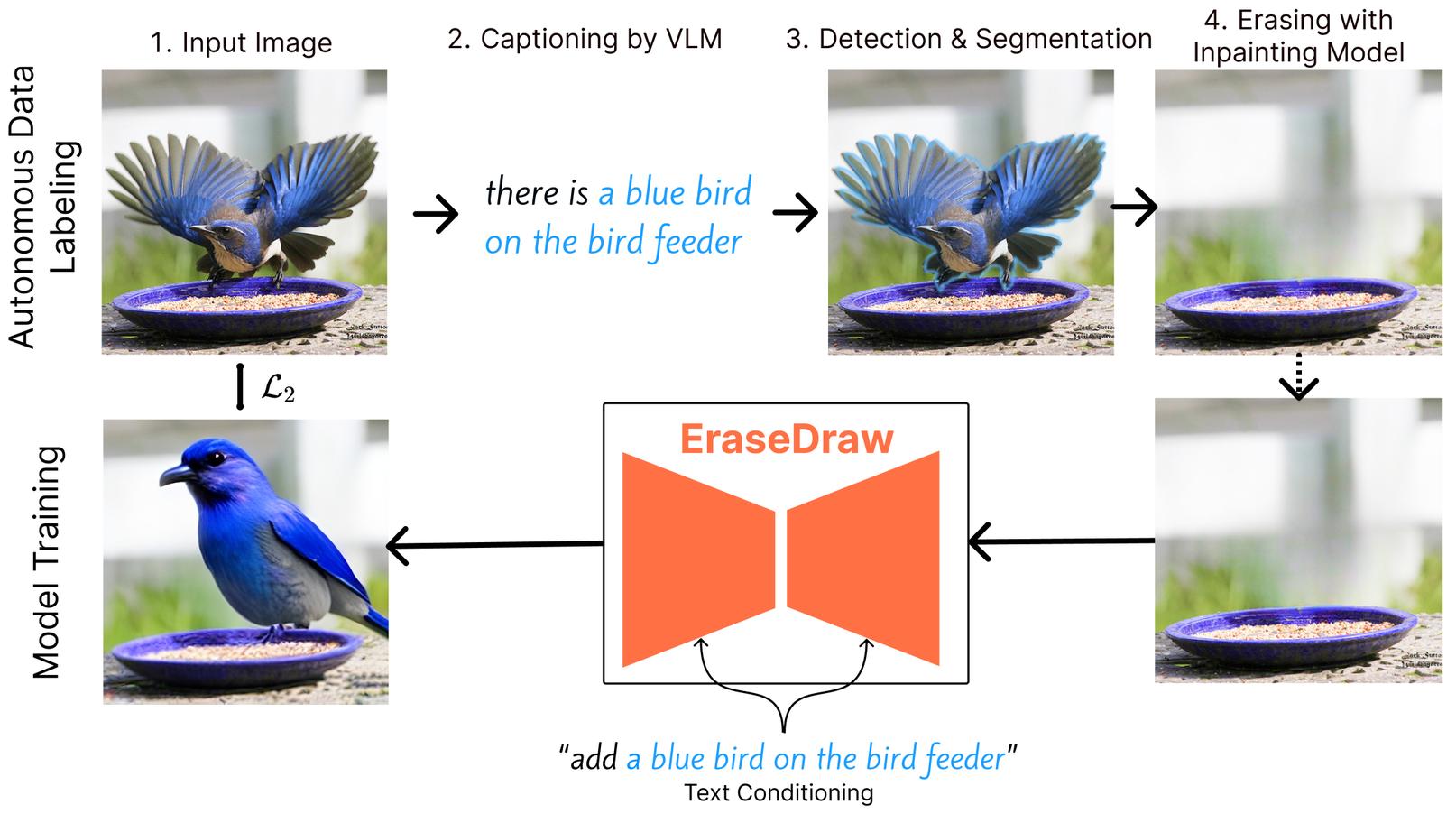
Results
EraseDraw can insert non-rigid, occluded, and transparent objects in a scene-aware manner.
Single-Step Insertions

Iterative Insertions
By repeatedly invoking EraseDraw, we can step-by-step compose complex images that cannot be achieved by the base model itself. This process can either be guided by a human user, or a large language model.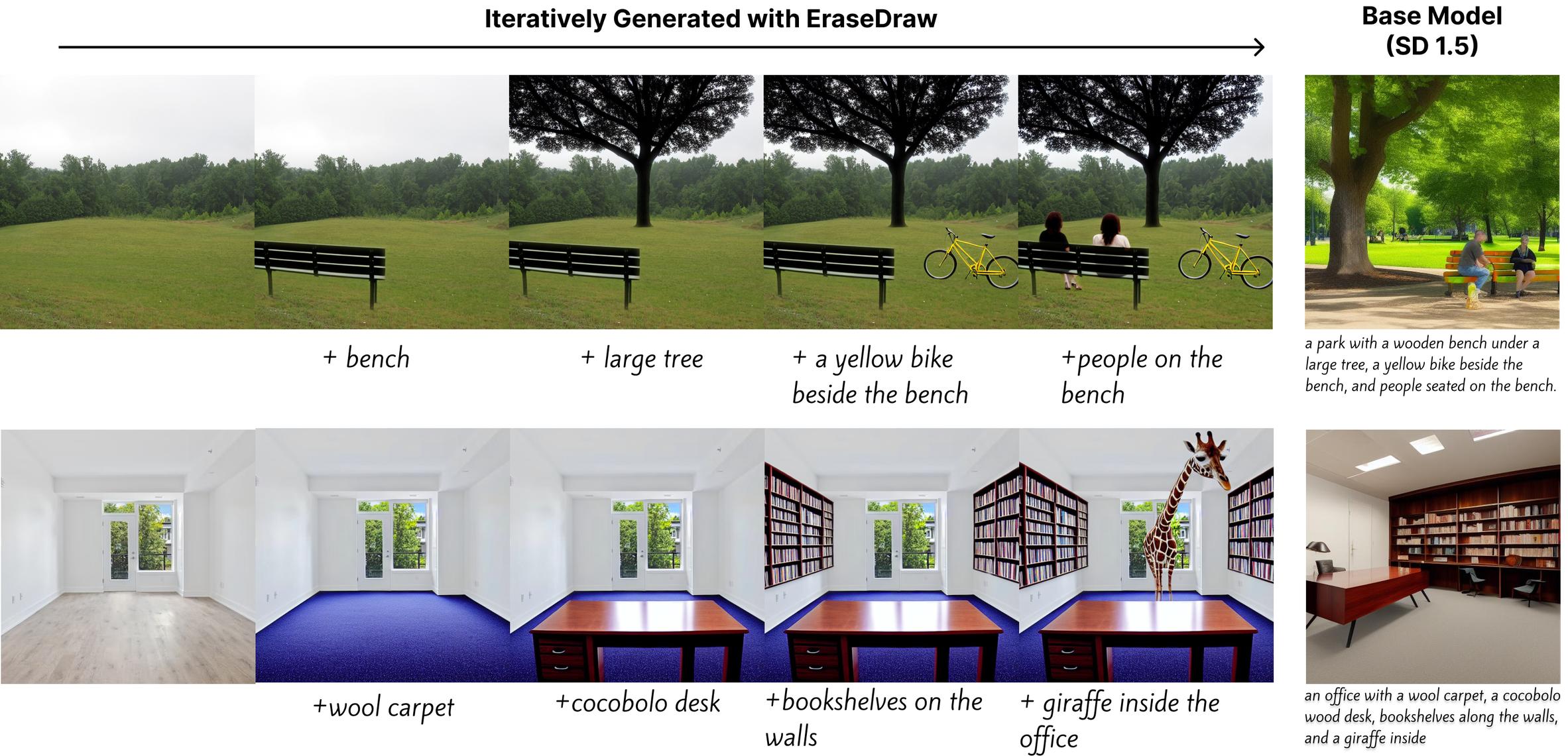
Modeling Natural Distribution of Objects
Sampling from our model reveals where objects naturally appear in the world. This opens up applications where commonsense knowledge about object placements are required, such as embodied agents.

Qualitative comparison to other methods
We evaluate our method against other publicly available instruction-guided editing models on the EmuEdit benchmark, and we find that our method can insert high-quality objects into a scene in a scene-aware manner while also preserving the rest of the image. We also include quantitative results in the paper.

format_quote Citation
@article{erasedraw-24,
title={EraseDraw: Learning to Draw Step-by-Step via Erasing Objects from Images},
author={Canberk, Alper and Bondarenko, Maksym and Ozguroglu, Ege and Liu, Ruoshi and Vondrick, Carl},
booktitle={ECCV 2024},
year={2024}
}
Acknowledgements
The authors would like to thank for Huy Ha, Samir Gadre, and Zeyi Liu, and the Columbia CV Lab valuable feedback and discussions. This project is partially supported by research from the DARPA ECOLE program and NSF NRI #1925157.
This webpage template was inspired by this project page.